System Architecture
🏗️ For Developers & Code Reviewers
This page explains how all files in ScholaRAG connect and communicate. Essential reading for contributors, code reviewers, and AI assistants.
High-Level Architecture
User (via Claude Code)
↓
prompts/*.md (Stage 1-7 conversation flows)
↓
scholarag_cli.py (Orchestration & initialization)
↓
config.yaml (Project configuration)
↓
scripts/*.py (Automated pipeline execution)
↓
data/ (Processed results)
↓
outputs/ (Final RAG system + PRISMA diagram)ScholaRAG follows a layered architecture where each layer has a specific responsibility:
- Conversation Layer: prompts/*.md guide users through decisions
- Configuration Layer: config.yaml stores all project settings
- Orchestration Layer: scholarag_cli.py coordinates script execution
- Execution Layer: scripts/*.py process data
- Data Layer: data/ folders store intermediate results
File Dependency Map
This diagram shows the complete file dependency flow in ScholaRAG, organized into 4 distinct layers. Each layer has a specific role in the automated research pipeline.
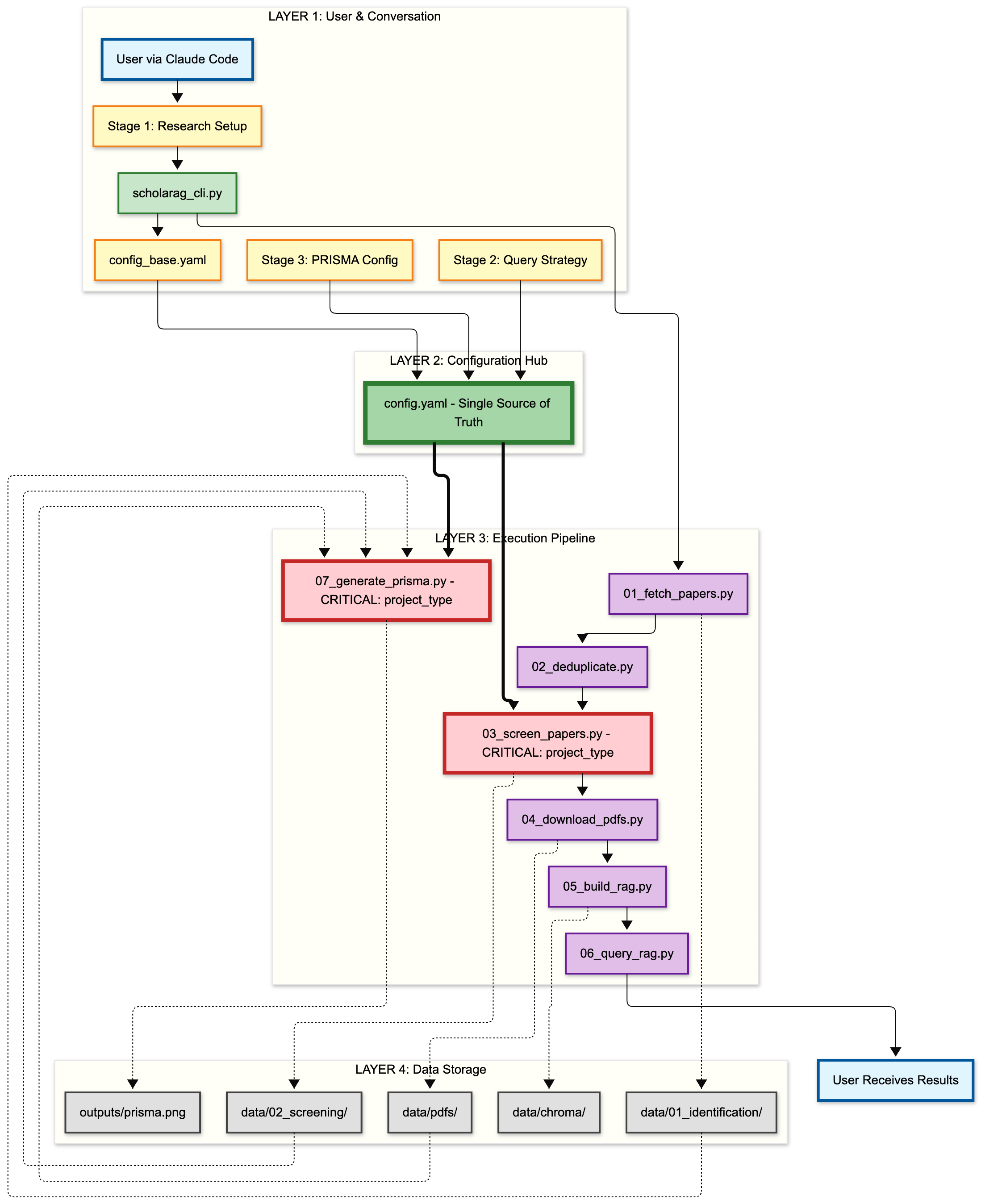
🔴 Critical: project_type Branching
Red nodes (03_screen_papers.py, 07_generate_prisma.py) read project_type from config.yaml and adjust their behavior accordingly. Thick red arrows (==>) indicate critical branching points.
- 03_screen_papers.py: Sets screening threshold (50% for knowledge_repository, 90% for systematic_review)
- 07_generate_prisma.py: Changes PRISMA diagram title based on project type
config.yaml: The Central Hub
config.yaml is the single source of truth for all project settings. Every script reads from it, making it the most important file in the system.
Critical Fields by Script
| Script | Reads From config.yaml | Why It Matters |
|---|---|---|
| 01_fetch_papers.py | search_query, databases | Determines which databases to query and what keywords to use |
| 03_screen_papers.py | project_type,ai_prisma_rubric | Critical: Sets screening thresholds (50% for knowledge_repository, 90% for systematic_review) |
| 05_build_rag.py | rag_settings.embedding_model, rag_settings.llm | Determines quality and cost of RAG system |
| 06_query_rag.py | rag_settings.llm, rag_settings.temperature | Controls answer generation quality and randomness |
| 07_generate_prisma.py | project_type,project_name | Critical: Changes diagram title based on project type |
💡 Design Principle
Scripts never hardcode values. Everything comes from config.yaml, making projects portable and reproducible.
Data Flow: Stage by Stage
01_fetch_papers.py
Fetches papers from Semantic Scholar, OpenAlex, arXiv using configured query
02_deduplicate.py
Removes duplicates by DOI, arXiv ID, and title similarity
03_screen_papers.py
⚠️ CRITICAL: Adjusts screening threshold based on project_type
04_download_pdfs.py
Downloads PDFs from open_access URLs with retry logic
05_build_rag.py
Chunks PDFs, generates embeddings, stores in vector database
06_query_rag.py
Retrieves relevant chunks, generates answers with citations
07_generate_prisma.py
⚠️ CRITICAL: Title changes based on project_type
AI Assistant Integration: CLAUDE.md + Skills + Scripts
🤖 Three-Layer Architecture for Claude Code
ScholaRAG uses a complementary three-layer system where CLAUDE.md, skills/, and scripts/ work together without conflict. Each layer activates at different times and serves different purposes.
Layer Architecture
┌─────────────────────────────────────────────────────────────┐
│ Layer 1: CLAUDE.md (Foundation - Always Active) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ • Loaded when Claude Code opens ScholaRAG directory │
│ • Provides base behavior rules, automation principles │
│ • Defines researcher profile, detection patterns │
│ • Handles: "I want to review AI chatbots" → Stage 1 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Layer 2: skills/ (Knowledge - Conditional Load) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ • SKILL.md → Entry point (Claude Skills feature) │
│ • skills/claude_only/ → Detailed stage guides │
│ • skills/reference/ → API docs, decision trees │
│ • Triggered: "Help me with Stage 3" or stage transition │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ Layer 3: scripts/ (Execution - After Completion) │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ • Actual Python code execution │
│ • 01_fetch_papers.py → 07_generate_prisma.py │
│ • Called when stage conversation completes │
└─────────────────────────────────────────────────────────────┘When Each Layer Activates
| Scenario | CLAUDE.md | skills/ | Result |
|---|---|---|---|
| User opens ScholaRAG folder | ✅ Active | ⏸ Standby | Base rules loaded |
| "I want to review AI chatbots" | ✅ Pattern detected | ⏸ Standby | Stage 1 starts |
| "Help me with Stage 3" | ✅ Active | ✅ Loaded | Detailed PRISMA guide |
| Stage 1 → Stage 2 transition | ✅ Active | ⚡ Auto-load | Query strategy guide |
| Stage conversation completes | ✅ Active | ✅ Active | scripts/*.py executed |
Why This Works: No Conflicts
📘 CLAUDE.md
Always-on foundation
- • Detection patterns
- • Researcher profile
- • Automation rules
- • CLI command formats
🎯 skills/
Extended knowledge
- • Stage conversation flows
- • Turn-by-turn patterns
- • Divergence handling
- • API reference details
⚙️ scripts/
Actual execution
- • Python implementation
- • API calls
- • Data processing
- • File I/O
💡 Key Insight
Skills enhance but don't replace CLAUDE.md. Even without explicit skill triggers, CLAUDE.md provides sufficient guidance. Skills add detailed conversation patterns for complex stages, making them complementary, not competing.
File Structure
Example Workflow
Common Pitfalls for Contributors
Adding a new field to config.yaml
❌ Problem: You add a field but forget to update documentation
- 1. Update
templates/config_base.yamlwith inline comments - 2. Update relevant
prompts/*.mdto collect this field - 3. Update relevant
scripts/*.pyto read this field - 4. Update
ARCHITECTURE.mdto document dependencies - 5. Update
RELEASE_NOTES_vX.X.X.md
Changing project_type logic
❌ Problem: You modify thresholds but only update one script
- Files to update:
03_screen_papers.py,07_generate_prisma.py - Prompts to update:
01_research_domain_setup.md,03_prisma_configuration.md - Template to update:
templates/config_base.yaml - Search for all occurrences:
grep -r "project_type" .
Creating a new script
❌ Problem: Script reads config but doesn't validate required fields
- 1. Add
load_config()method to validate required fields - 2. Use
self.config.get('field', default_value)with safe defaults - 3. Print clear error messages: "❌ Missing required field: X"
- 4. Add script to dependency map in
ARCHITECTURE.md
Quick Reference Tables
Where is X defined?
| What | Defined In | Used By |
|---|---|---|
| project_type | config.yaml (Stage 1) | 03_screen_papers.py, 07_generate_prisma.py, all prompts |
| search_query | config.yaml (Stage 2) | 01_fetch_papers.py |
| ai_prisma_rubric | config.yaml (Stage 3) | 03_screen_papers.py |
| rag_settings | config.yaml (Stage 4) | 05_build_rag.py, 06_query_rag.py |
| API keys | .env (Stage 5) | 03_screen_papers.py, 05_build_rag.py, 06_query_rag.py |
Script Execution Order
Ready to Contribute?
Now that you understand the architecture, check out the detailed script documentation to see how each component works internally.
View Script Documentation →